Backing up your machines
Wed October 11 2017 by Christopher AedoUPDATE: OSX Catalina introduced new security around disk access which prevented borg from accessing some directories. I documented a fix for that here.
TL;DR After CrashPlan discontinued their home plan I found a good solution using open source software and an inexpensive yet reliable cloud storage provider. I've got automated replicated backups now using Borg, Rclone and Wasabi cloud storage - details below.
Several years ago I started using CrashPlan to back up one of my machines at home. Soon after, I signed up for the family plan and added more machines, including computers belonging to my siblings and my wife. The fact that it was essentially "always on" and doing frequent backups without ever having to think about it was fantastic. Additionally, the ability to do point-in-time restores came in handy on several occasions. Since I'm generally the IT guy for the family, I loved that the user interface was so easy to use. There were several times when someone in the family needed to recover all their data and they didn't need my help.
Recently CrashPlan announced that they were dropping the consumer customers and focusing on their enterprise customers. It makes sense I suppose, they were not making a lot of money off folks like me, and across our family plan we were using a whole lot of storage on their system.
In looking for a suitable replacement, there were several features any solution needed to have:
- Cross-platform support for Linux and Mac
- Automated, so there's no need to remember to click "backup"
- Point-in-time recovery (or something close) so if you accidentally delete a file but don't notice until later, it's still recoverable
- Inexpensive
- Replicated data store for backup sets, so data exists in more than one place (i.e. not just backing up to a local USB drive)
- Encrypted in case the backup files should fall into the wrong hands
As I looked for services similar to CrashPlan I googled around and asked my friends. One said he was using Arq Backup and was really happy with them, but no Linux support meant it was no good for me. Carbonite is similar to CrashPlan but would be expensive for my case since I've got multiple machines to backup. Backblaze offers unlimited backup at a good price ($5/month) but doesn't support Linux for their backup client, or at least they did not as of this writing. There were a few other options I looked at but none of them matched everything I was looking for. That meant I got to figure out a good approach to replicating what CrashPlan delivered for me and my family. I think what I worked out came out pretty close.
I knew there were lots of good options for backing up files on Linux systems. In fact I've been using rdiff-backup for at least ten years. This was usually for saving snapshots of remote filesystems locally. I had hopes of finding something that would do a better job of deduplicating backup data though, since I knew there were going to be some things (like music libraries and photos) that would potentially be duplicated on multiple computers.
BackupPC was also a really strong contender, but to be honest I had already gone a ways down the road of testing with my chosen solution before I was reminded of BackupPC.
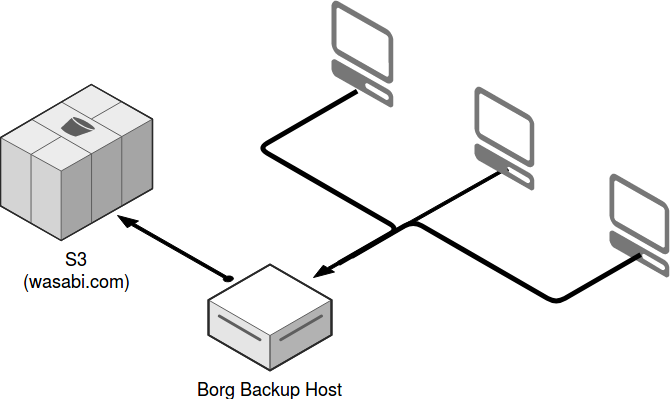
Ultimately I landed on using Borg Backup and couldn't be happier with my decision. It fit all the criteria I listed above, and has a pretty healthy community of users and contributors. Borg offers de-duplication and compression, and works great on PC, Mac and Linux. Then I use Rclone to synchronize the backup repositories from the Borg host up to S3 compatible storage on Wasabi. Any S3-compatible storage will work for this, but I chose Wasabi because their price can't be beat and they out-perform Amazon's S3. With this setup I can restore files from the local Borg host or from Wasabi.
Installing Borg on my machine was as simple as "sudo apt install borgbackup". For the backup host I have one Linux machine that's always on, and a 1.5TB USB drive attached to it. This backup host could be something as lightweight as a Raspberry Pi if you don't already have a machine available for this. Just make sure all the client machines are able to reach this server over SSH.
It's important to limit which commands the client machines are able to execute when they connect to your backup server. The easiest way to do this is to set this in the .ssh/authorized_keys file by prepending each host with a "command" setting such as:
command="cd /mnt/backup/mycomputer; borg serve --restrict-to-path
/mnt/backup/mycomputer/" ssh-rsa AAAAB3NzaC1yc2EAA[...] me@mycomputer
On the backup host, you can initialize a new backup repository with:
$ borg init /mnt/backup/repo1
Depending on what you're backing up, you might choose to make multiple repositories per machine, or possibly one big repository for all your machines. Since Borg de-duplicates, if you have identical data on many computers it might make sense to send backups from all those machines to the same repository.
Installing Borg on the Linux client machines was very
straightforward. On OSX I needed to install XCode and Homebrew
first. I followed this
how-to
to install the command line tools, and then used "homebrew install
borgbackup". On the Apple machines I used a LaunchAgent to
kick off the backup runs on schedule each night. That requires
a plist file and then running "launchctl load
Each of the machines have a backup.sh script (contents below) that is kicked off by cron at regular intervals. It will only make one backup set per day, so it doesn't hurt to try a few times in the same day. The laptops are set to try every two hours because there's no guarantee they will be on at a certain time, but it's very likely they'll be on during ONE of those times. This could be improved by writing a daemon that's always running and triggers a backup attempt any time the laptop wakes up. For now though I'm happy with the way things are working.
I could skip the cron job and provide a relatively easy way for each user to trigger a backup using BorgWeb but I really don't want anyone to have to remember to back things up. In my personal experience I tend to forget to click that backup button until I'm in dire need of a restoration (at which point it's way too late!)
The backup script I'm using came from the Borg docs quickstart, plus I added a little check at the top to see if borg is already running, so the script will exit if the previous backup run is still in progress. This script makes a new backup set and labels it with the hostname and current date. It then prunes old backup sets with an easy to understand retention schedule.
backup.sh:
#!/bin/sh
REPOSITORY=borg@borgserver:/mnt/backup/repo1
borgpid=$(ps aux | grep -v grep | grep borg | wc -l)
#Bail if borg is already running, maybe previous run didn't finish
if [ $borgpid -gt 0 ]; then
echo "Backup already running"
exit
fi
# Setting this, so you won't be asked for your repository passphrase:
export BORG_PASSPHRASE='This is not the real passphrase'
# Backup all of /home/doc except a few
# excluded directories
borg create -v --stats \
$REPOSITORY::'{hostname}-{now:%Y-%m-%d}' \
/home/doc \
--exclude '/home/doc/.cache' \
--exclude '/home/doc/.local' \
--exclude '/home/doc/.mozilla' \
--exclude '/home/doc/.config/google*' \
--exclude '/home/doc/.minikube' \
--exclude '/home/doc/Downloads' \
--exclude '/home/doc/Videos' \
--exclude '/home/doc/Music'
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
# archives of THIS machine. The '{hostname}-' prefix is very important to
# limit prune's operation to this machine's archives and not apply to
# other machine's archives also.
echo "Pruning expired archives"
borg prune -v --list $REPOSITORY --prefix '{hostname}-' \
--keep-daily=7 --keep-weekly=4 --keep-monthly=6
The output from a backup run looks like this:
------------------------------------------------------------------------------
Archive name: x250-2017-10-05
Archive fingerprint: xxxxxxxxxxxxxxxxxxx
Time (start): Thu, 2017-10-05 03:09:03
Time (end): Thu, 2017-10-05 03:12:11
Duration: 3 minutes 8.12 seconds
Number of files: 171150
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 27.75 GB 27.76 GB 323.76 MB
All archives: 3.08 TB 3.08 TB 262.76 GB
Unique chunks Total chunks
Chunk index: 1682989 24007828
------------------------------------------------------------------------------
[...]
Keeping archive: x250-2017-09-17 Sun, 2017-09-17 03:09:02
Pruning archive: x250-2017-09-28 Thu, 2017-09-28 03:09:02
Once I had all the machines backing up to the host, I followed the instructions for installing a precompiled rclone binary, and set it up to access my wasabi account. You can find details on using rclone with Wasabi here.
This script runs each night to synchronize any changes to the backup sets. It checks to make sure the directory it is attempting to sync is actually using a reasonable amount of space and will exit entirely if not. This should prevent the script from accidentally wiping out a remote storage bucket if it accdentally tries to synchronize an empty directory. It also skips that test for one really small backup repository. Finally, it emails a summary report of the backup activity:
#!/bin/bash
#set -e
repos=( repo1 repo2 repo3 webserver80 )
export BORG_PASSPHRASE='This is not the real passphrase'
#Bail if rclone is already running, maybe previous run didn't finish
if pidof -x rclone >/dev/null; then
echo "Process already running"
exit
fi
for i in "${repos[@]}"
do
REPOSITORY=borg@borgserver:/mnt/backup/$i
if borg check $REPOSITORY &> /dev/null
then
echo "Borg check passed for $REPOSITORY" >> /tmp/wasabi-mail.log
/usr/bin/rclone -v sync /mnt/backup/$i wasabi:$i > /tmp/wasabi-sync.log 2>&1
cat /tmp/wasabi-sync.log >> /home/borg/wasabi-sync.log
/usr/bin/borg list $REPOSITORY > /tmp/borg-list 2>&1
tail -n 5 /tmp/borg-list >> /tmp/wasabi-mail.log
head -n 1 /tmp/wasabi-sync.log >> /tmp/wasabi-mail.log
tail -n 6 /tmp/wasabi-sync.log >> /tmp/wasabi-mail.log
else
echo "Problems found with consistency check on $REPOSITORY" >> /tmp/wasabi-mail.log
fi
done
cat /tmp/wasabi-mail.log | mail -s "Backup report" doc@aedo.net
rm -f /tmp/wasabi-mail.*
The first synchronization of the backup set up to Wasabi with rclone took several days, but that was because it was around 400gb of new data and my outbound connection is not super fast. Since then the daily delta is very small and completes in just a few minutes.
Restoring files is NOT as easy as it was with CrashPlan, but it is relatively straightforward. The fastest approach is to restore from the backup stored on the Borg backup server. Here are some example commands used to restore.
#List which backup sets are in the repo
$ borg list borg@borgserver:/mnt/backup/repo1
Remote: Authenticated with partial success.
Enter passphrase for key ssh://borg@borgserver/mnt/backup/repo1:
x250-2017-09-17 Sun, 2017-09-17 03:09:02
#List contents of a backup set
$ borg list borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 | less
#Restore one file from the repo
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc/somefile.jpg
#Restore a whole directory
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc
If something happens to the local Borg server or the USB drive holding all the backup repositories, I can also easily restore directly from Wasabi. The machine needs to have rclone installed, and then using rclone mount I can mount the remote storage bucket as though it were a local filesystem.
#Mount the S3 store and run in the background
$ rclone mount wasabi:repo1 /mnt/repo1 &
#List archive contents
$ borg list /mnt/repo1
#Extract a file
$ borg extract /mnt/repo1::x250-2017-09-17 home/doc/somefile.jpg
Now that I've been using this backup approach for a few weeks I can say I'm really happy with it. Setting everything up and getting it running was a lot more complicated than just installing CrashPlan of course, but that's the difference between rolling your own solution and using a service. I will have to watch this more closely to be sure backups continue to run and the data gets properly synchronized up to Wasabi. But in general replacing CrashPlan with something offering comparable backup coverage at a really reasonable price turned out to be a little easier than I expected. If you see room for improvement please let me know!